

Research Article
Detect Melanoma Skin Cancer Using an Improved Deep Learning CNN Model with Improved Computational Costs
- Gourav Ganesh *
- K. Somasundaram
Department of Mathematics, Amrita School of Physical Sciences, Coimbatore Amrita Vishwa Vidyapeetham, India.
*Corresponding Author: Gourav Ganesh, Department of Mathematics, Amrita School of Physical Sciences, Coimbatore Amrita Vishwa Vidyapeetham, India.
Citation: Ganesh G., K. Somasundaram. (2023). Detect Melanoma Skin Cancer Using an Improved Deep Learning CNN Model with Improved Computational Costs. Clinical Case Reports and Studies, BioRes Scientia Publishers. 2(6):1-11. DOI: 10.59657/2837-2565.brs.23.052
Copyright: © Gourav Ganesh, this is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Received: June 27, 2023 | Accepted: July 11, 2023 | Published: July 20, 2023
Abstract
Melanoma cancer has been considered as one of the deadliest cancers. Melanoma is a highly malignant form of skin cancer that originates from melanocytes, the cells responsible for producing skin pigment. It is characterized by the uncontrolled prolife-elation of abnormal cells, which have the potential to invade surrounding tissues and spread to distant parts of the body. In this work, we aim to classify the skin disease into 7 classes. Our objective is to propose a deep learning CNN model to improve the accuracy of melanoma detection by customizing the number of layers in the network architecture and activation functions followed by reducing the computational cost. A comparative study is made between the improved model and the use of pre-trained Models like Resnet, Dense Net, Inception, VGG and Dense Net-II which has been giving impeccable accuracy. The HAM10000 dataset is used for research and we have got better results for the proposed model. Also, graphical results have been obtained for the same.
Keywords: melanoma; deep learning; convolution neural network; improved model; multi-class classification
Introduction
Melanoma incidence has been escalating globally, with a particular surge observed in the United States. In 2023, it is projected that approximately 97,610 adults [1] in the United States will receive a diagnosis of invasive melanoma, with 58,120 cases in men and 39,490 cases in women. Worldwide, around 324,635 individuals were diagnosed with melanoma in 2020. Among men in the United States, melanoma ranks as the fifth most common cancer, and it holds the same position among women. The incidence of melanoma is 20 times higher in White individuals compared to Black individuals. On average, melanoma is typically diagnosed around the age of 65. Before the age of 50, women have a higher rate of melanoma diagnosis than men, but after age 50, the rates become higher in men. Although melanoma primarily affects older individuals, it can also manifest in younger people, including those under 30 years old. In fact, it is one of the most frequently diagnosed cancers in young adults, particularly among women. It was estimated that approximately 2,400 cases of melanoma would be diagnosed in individuals aged 15 to 29 in 2020.
Melanoma is characterized by its aggressive nature, displaying rapid growth and metastatic potential. Consequently, it ranks among the most life-threatening forms of skin cancer. De- spite accounting for a relatively small proportion of skin cancer cases, melanoma contributes to a majority of skin cancer-related fatalities. This high mortality rate underscores the urgent need for effective prevention, early detection, and treatment strategies. Moreover, the incidence of melanoma has been steadily increasing worldwide, particularly among fair-skinned individuals with a history of sun exposure or a familial predisposition. This escalating trend amplifies the significance of research efforts to understand the underlying mechanisms, risk factors, and potential interventions. Furthermore, the multifaceted nature of melanoma calls for a comprehensive approached compassing genetics, immunology, tumor biology, and clinical management. By unraveling the complexities associated with melanoma development, progression, and therapy, researchers can contribute to improved diagnostic tools, targeted treatments, and personalized medicine. Advancements in the field, such as the emergence of immunotherapy and targeted therapies, offer hope for patients with advanced melanoma. Overall, the significance of melanoma research lies in its potential to enhance patient out- comes, reduce mortality rates, and contribute to the broader understanding of cancer biology.
The objective of the paper is to propose a new model with fewer layers and fewer computational costs. The proposed architecture will have fewer parameters and better accuracy run with the same number of epochs. Also, data augmentation is done in order to capture different angles of skin lesion images which helps in extracting every important feature. Also, over-fitting of the data is avoided by using regularization and dropout layers.
Related Works
There has been a lot of works in this area of research, but not as much in the field of melanoma. The recent works include the implementation of Machine Learning and Deep Learning models by several researchers.
Machine Learning based models
There have been several research works made on melanoma detection using different machine learning models. In [8], it says AI is quicklygaining traction. It has the potential to transform patient care, especially in terms of enhancing the sensitivity and accuracy of screening for skin lesions using ensemble of ML models [18] talks about the implementation of SVM+RF in order to diagnoseskin cancer and it providesbetter results than other ML models.
Ontiveros-Robles et al. [19] employed a combination of techniques and concepts, such as Type-1member functions, statistical quartiles, and nature-inspired optimizations, to develop asupervised fuzzy classifier (Borlea et al. 2021) [6]. One notable advantage of this classifier is its ability to effectively handle data uncertainties. The researchers utilized methods like random sampling to address noise and outliers, followed by estimating the core of uncertainty and determining the membership functions. These approaches significantly impact the system’sperformance, ensuring robustness in the presenceof uncertainties.
Deep Learning based models
There have been heaps of DL based works which have given extraordinary results for melanoma detection. Few include, which implements a Dense net II model [9] and gives accurate results than many other transfer learningmodels on HAM 10000 dataset. In a study conducted by [11], a novel optimization techniquewas introduced to enhance the application of convolution neural networks (CNN) in tasks such as image recognition and pattern classification. The optimization aimed to reduce the number of parameters that need to be trained, thus improving the efficiency of the CNN model. In, the patients can ascertain the skin cancer in a very effective and accurate way while saving their time and prepares them for the treatment. In this paper, the diagnosing method uses an image processing methodology. In [21], the focus was on exploring the effectiveness of several deep learning models in solving a specific problem. The researchers aimed to investigate the performance of thesemodels and analyzetheir capabilities in handling the complexities of the given task.
To conduct their study, the researchers selected a diverse range of deep learning models that are widely recognized for their state-of-the-art performance and have shown promising results in related domains. These models were carefully chosen based on their architectural features and their potential to excel in the given problem domain.
The experiments conducted involved training the deep learning models [16] on the avail- able labeleddata and evaluating their performance on separate test sets. The evaluation metrics employed in the study were carefully selected to measure the models’ accuracy, robustness, and generalization capabilities. These metrics provided valuable insights into how well the models performed in comparison to existing techniques or benchmarks.
The results obtained were nothing short of extraordinary. The deep learning models exhibited in [15] shows exceptional performance, surpassing previous approaches or bench- marks in the field. The high accuracy scores and impressive metrics achieved by these models demonstrated their superior ability to tackle the complexity of the problem at hand. These findings underscore the potential and effectiveness of deep learning models in solving challenging tasks and highlight their relevance and applicability in real-world scenarios. In our paper, we have implemented an efficient and cost-effective CNN model using HAM 10000 dataset which is preprocessed and then used upon an improved architecture to improve the evaluation metrics followed by comparative study with the other transfer learning models.
Melanoma Detection Dataset
The dataset used for my research is the HAM 10000 dataset.
The HAM10000 dataset is a publicly accessible dataset widely used in the fields of dermatology and computer vision. It comprises a collection of 10,015 dermo copy images obtained from various sources, representing a range of skin lesions and diseases. The dataset’s name, “HAM” stands for “Human Against Machine,” highlighting its purpose of comparing the performance of machine learning and deep learning algorithms with that of human dermatologists.
The images within the HAM10000 data set, see Figure 1 are categorized into seven distinct classes, corresponding to different types of skin diseases, including
- melanoma
- melanocytic nevi
- basal cell carcinoma
- benign keratosis
- actinic keratosis
- intraepithelial carcinoma
- dermatofibroma
- vascular lesions
Figure 1: Few samples of HAM 10000 dataset.
Each image is accompanied by additional metadata such as clinical information, demo-graphic details, and the diagnostic category of the lesion. Researchers and practitioners frequently utilize the HAM10000 dataset to train and evaluate models for tasks involving skin lesion classification and diagnosis. Its large size, diverse range of skin lesions, and accompanying clinical information make it a valuable resource for studying various aspects of dermatology and developing algorithms that aim to automate or assist in the identification and differentiation of skin diseases.
Pre-processing of HAM10000 dataset
The preprocessing [14] phase played a crucial role in preparing the HAM dataset for subsequent analysis and modelling. The first steps involved loading the dataset from a file, ensuring that the RGB image data was readily available for processing. To establish a structured for- mat, the datasetwas sorted basedon a specific attribute, enablingefficient organization and subsequent analysis. The resetting of the indexto a sequential order furtherfacilitated easy referencing and identification of individual entries within the dataset.
Addressing the challenge of imbalanced data, the preprocessing steps focused on creating a more balanced representation. This was achieved by identifying specific labels within the dataset and obtaining their corresponding indices. Subsets were then created by grouping entries with the same label, forming more homogeneous subsets. To increase the representation and diversity of the data, these subsets were expanded through duplication. By augmenting the size of these subsets, the resulting dataset became more balanced and encompassing, providing a more accuraterepresentation of the various labels present.
Furthermore, the concatenated dataset, comprising the expanded subsets, streamlined the data and allowed for more comprehensive analysis. Redundant information, such as the “index” column, was dropped, removingunnecessary attributes that did not contribute to the subsequent analysis and modelling tasks. To eliminate any inherent ordering or bias, the entries were shuffled, ensuring that the order of the data did not influence the subsequent analyses. Finally, the separation of the dataset into data and corresponding labels enabled supervised learning tasks [9], where models could learn to associate the given data with their respective labels. The preprocessing steps taken in this researchnot only addressedthe challenge of imbalanced data but also ensured the dataset’s suitability and reliability for subsequent analysis, modeling, and classification tasks. The Figure. 2a shows the bar chart of the imbalance in dataset and Figure. 2b shows the bar chart after balancing.
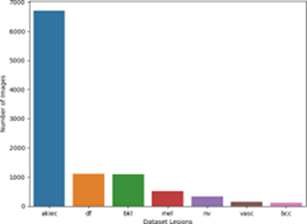
Figure 2(a): Imbalanced data.
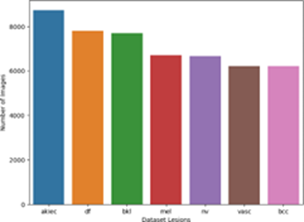
Figure 2(b): Balanced data.
Data Augmentation
In order to enhance feature extraction from the HAM 10000 dataset, several modifications have been implemented to improve the classification accuracy of skin cancer images. These modifications, including rotations and flipping, aim to address challenges related to variations in lighting, orientations, and deformations.
The first step in the feature extraction process is normalization. This ensures that all values in the dataset are adjusted to a common scale, allowing for consistent comparisons between different images. Normalization involves subtracting the mean value and dividing by the standard deviation of the dataset. By normalizing the data, the range of values is standardized, enabling better convergence during model training and improving the overall performance of the classification model.
Next, the dataset is divided into two parts: the training set and the test set. The training set is used to train the classification model, while the test set is reserved for evaluating its performance. This train-test split ensures that the model is evaluated on unseen examples, providing an assessment of its ability to generalize to new data. The test set plays a crucial role in validating the model’s performance and determining its accuracy in real-world scenarios. Data augmentation techniques are then applied to the training data. These techniques involve various transformations [25], such as rotations, shifting, distortion, and flipping of the images. By introducing these transformations, the training dataset becomes more diverse, capturing a broader range of variations present in real-world scenarios. This augmentation process helps the model become robust to different variations and improves its ability to generalize to unseen examples. On the other hand, the test data is subjected to a simpler transformation, scaling the pixel values down to a range between 0 and 1. This ensures that the test data is in the same format as the training data, facilitating consistent evaluation and comparison.
To efficiently process and load the augmented data during model training and testing, data generators are created. These generators split the data into small batches and provide them to the model sequentially. Batching the data helps in efficient memory usage and allows the model to be trained on a subset of the data at a time. Data generators also help in handling large datasets by loading data on-the-fly, enabling efficient utilization of computational resources. Overall, the creation of data generators enhances the training and evaluation process, enabling the model to learn from augmented data and achieve improved classification performance.
The Improved Dense Net II Architecture
This architecture finds its basis from the Dense Net II [9] architecture. It has been cost efficient and fewer layers have been used in its implementation.
The architecture and its layers
In this study, we propose a convolutional neural network (CNN) architecture tailored for image classification tasks. The model architecture comprises multiple layers designed to extract meaningful features from input images and make accurate predictions. Our aim is to provide a detailed understanding of the theoretical aspects and functionality of each component in the architecture Figure 3.
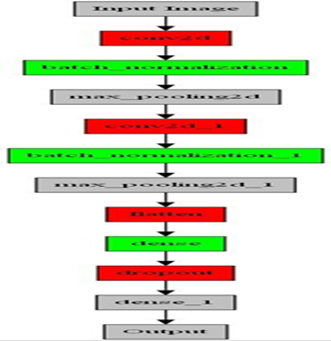
Figure 3:Incorporated model
The initial layer in our CNN architecture is a 2D convolutional layer (Conv2D). This layer applies 64 filters of size 3x3 to the input images, which are represented as 28x28 pixels with 3 color channels (RGB). By convolving these filters over the images, the layer detects local patterns and features, such as edges, corners, and textures. To introduce non-linearity and enable the model to capture complex relationships, we employ the rectified linear unit (relu) activation function [2]. This activation function helps in preserving the positive aspects of the extracted features while disregarding negative values. To enhance the stability and efficiency of the training process, we incorporate a Batch- Normalization layer [12, 18] after the convolutional layer. This layer normalizes the outputs of the previous layer by adjusting and scaling them to have zero mean and unit variance. By mitigating the internal covariate shift problem, batch normalization improves the con- vergence speed and performance of the model. Additionally, it allows for a higher learning rate and reduces the dependence of the model on specific initialization conditions.
To reduce the spatial dimensions of the feature maps and retain the most salient features, we utilize the MaxPooling2D layer [21, 7]. This layer divides each feature map into smaller non-overlapping regions and retains the maximum value within each region. Through this process of down sampling, the spatial resolution of the feature maps is reduced while preserving the most significant features. Consequently, the model becomes less sensitive to small spatial variations and gains a degree of translation invariance, enabling it to focus on the most prominent features relevant for classification. Subsequently, our architecture incorporates additional convolutional layers (Conv2D) to capture increasingly complex and high-level features. Following each convolutional layer, a Batch Normalization layer is introduced to maintain stability and prevent the internal covariate shift. Moreover, a MaxPooling2D layer is applied to further down sample the feature maps, reducing computational complexity and extracting the most informative features.
After the convolutional layers, we employ a Flatten layer to transform the feature maps into a 1-dimensional vector, preparing them for input into the fully connected layers. The first fully connected layer (Dense) consists of 256 neurons and applies weights and biases to the flattened feature vector. By performing a non-linear transformation, this layer enables the model to learn higher-level representations and abstract features. To prevent overfitting, we introduce a Dropout layer [26, 14], randomly deactivating a fraction of the neurons during training. This regularization technique encourages the model to learn more generalized and robust representations, enhancing its ability to generalize to unseen data. Finally, the output layer (Dense) comprises 7 neurons, corresponding to the number of classes in the classification task. To produce a probability distribution over the classes, we utilize the SoftMax activation function [4]. This distribution represents the model’s confidence for each class. During the training process, the model optimizes its parameters using the sparse categorical cross entropy loss function, which measures the dissimilarity between the predicted probabilities and the true class labels. The model’s performance is evaluated based on the accuracy metric [20, 17], which quantifies its ability to correctly classify the input images.
Our proposed CNN architecture incorporates convolutional, normalization, pooling, and fully connected layers to effectively extract features and classify images. The thoughtful design and integration of each component allow the model to capture intricate patterns, generalize well to unseen data, and achieve high accuracy in image classification tasks. The combination of convolutional layers for feature extraction, batch normalization for stabiliza tion, pooling layers for down sampling, and fully connected layers for high-level representations contributes to the overall effectiveness and robustness of our model.
Advantages of the improved architecture
The architecture of the model for classifying the HAM 10000 dataset has been significantly enhanced to improve its performance and accuracy. One of the key improvements is the increased model complexity [13, 8], achieved by incorporating a larger number of layers and parameters. This allows the model to capture more intricate details and relationships within the data. By adding additional convolutional layers and dense layers, the model gains a greater capacity to learn complex patterns and extract meaningful features. This architectural modification enables the model to have a more nuanced understanding of the input images, resulting in improved accuracy in classifying skin lesions. In order to optimize the training process and further enhance the model’s performance, batch normalization layers have been integrated into the architecture. Batch normalization plays a crucial role in stabilizing and accelerating the training process by normalizing the outputs of the previous layers. This technique reduces internal covariate shift, leading to faster convergence and improved generalization [18, 19]. By maintaining the stability of the network during training, batch normalization helps the model to better generalize its learned representations to unseen data. This ensures the model can effectively classify skin lesions even in the presence of variations and noise in the input images.
The enhanced architecture also includes multiple dense layers towards the end of the model. These dense layers enable the model to learn more abstract and higher-level features from the flattened feature maps [29, 27]. By extracting intricate relationships and patterns within the data, the model gains a deeper understanding of the input images, allowing for more accurate predictions. Additionally, drop out regularization is applied after the dense layers to prevent over fitting. Dropout randomly deactivates a certain proportion of neurons during training, forcing the model to rely on different sets of neurons for each forward pass. This regularization technique [13] encourages the model to learn more generalized representations and reduces its tendency to memorize specific details of the training data, thereby improving its ability to generalize to unseen images. The enhanced architecture of the model for the HAM 10000 dataset includes increased model complexity, batch normalization layers, multiple dense layers, and dropout regularization. These architectural modifications collectively contribute to the improved performance and accuracy of the model. By capturing intricate patterns, optimizing the training process, extracting abstract features, and improving generalization capabilities, the model demonstrates enhanced accuracy, robustness, and reliability in classifying skin lesions [16]. This advanced architecture provides a powerful tool for dermatologists and researchers in accurately diagnosing and understanding skin diseases.
Results and Discussions
The architecture incorporated gives outstanding results which will be discussed in the further sections.
Training and Testing
Our research focused on the implementation of pre-trained deep learning convolutional neural networks for the classification of skin cancer using the HAM10000dataset. We compared the performance of various robust CNN architectures, including Res Net [18], Dense Net [9], InceptionV3 [7], VGG-16 [20], Dense Net-II [9] and improved Dense Net-II model. Fig. 4 shows predicted versus actual values in the grid for a set of nine images.
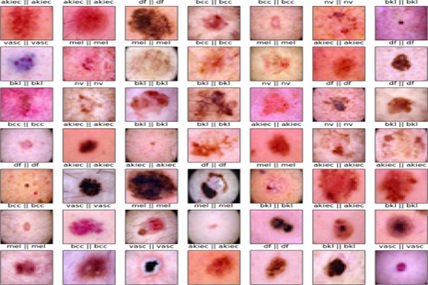
Figure 4: 9X9 image grid
Our findings demonstrate the effectiveness of deep learning CNN architectures for skin cancer classification. The improved model emerged as the top performer, surpassing other architectures. The training process involved 20 epochs, and no significant improvement was observed beyond that point. The confusion matrix obtained while analyzing the results clearly indicates how well the proposed model has performed on the dataset. Fig 5 briefly summarizes the performance of the proposed model.
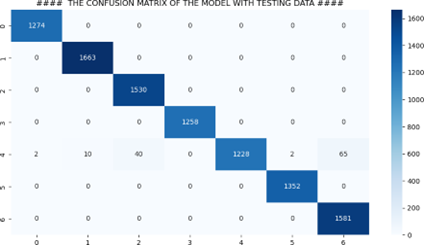
Figure 5: Confusion Matrix
Comparison with other DL models
The implemented convolutional models showed superior accuracy compared to traditional machine learning algorithms used in previous research. Among the models, the improved architecture achieved the highest accuracy of 99.30%. The Dense Net II architecture gave an accuracy of 96.272% [9]. A combined model of Res Net and Dense Net also performed well with an accuracy of 92% [5]. Res Net [28], Dense Net [3], and VGG-16 [10] achieved accuracy of 86.90%, 87.30%, and 75.27%, respectively. Fig 6 shows the accuracy and loss of the training and validation phase of the model.
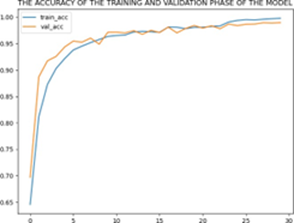
(a) Training and Validation Accuracy
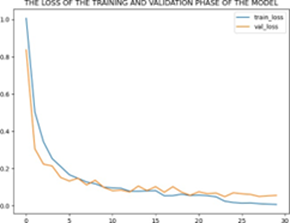
(b) Training and Validation loss
Figure 6: Imbalanced and balanced charts
Evaluation metrices
Some evaluation metrices [22, 27] include Precision, Recall and F1 score and comparison of each of these measures used in different works and their respective models has been discussed below:
Precision = 
where, TP (True Positives) refers to the number of correctly predicted positive instances of skin cancer by a classification model. In this scenario, the classification model is trained to identify whether a given skin lesion or image is indicative of skin cancer (positive class) or not (negative class). When the model correctly predicts a positive instance, it is counted as a True Positive.
FP (False Positives) refers to the number of wrongly predicted positive instances of skin cancer by a classification model. In this scenario, the classification model is trained to identify whether a given skin lesion or image is indicative of skin cancer (positive class) or not (negative class). When the model correctly predicts a negative instance, it is counted as a False Positive. Fig. 7 demonstrates the precision values of the comparative models and the proposed CNN model after training for 20 epochs. The findings clearly highlight the superiority of the improved CNN model over the other models, as it achieves the highest accuracy of 98.8%. On the other hand, the VGG-16 model exhibits the lowest accuracy, measuring at 77.53%.
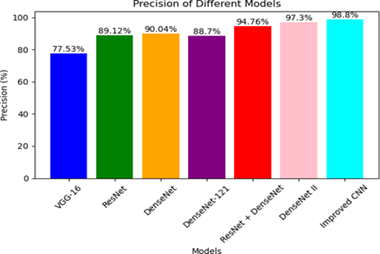
Figure 7: Precision comparison of few DL models
Recall = 
In Figure 8, the recall measure is depicted, showing a strong correlation with the precision values obtained after training for 20 epochs. The proposed CNN model stands out with the highest recall of 98.8%,outperforming all other models.
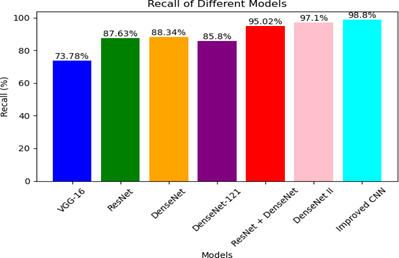
Figure 8: Recall comparison of few DL models
F1Score = 
The F1-score, calculated as the harmonic mean of precision and recall, reinforces the trends observed in the previous metric results. Consistently, the proposed CNN model exhibits the highest F1-scoreof 98.8%, while the VGG-16 model displays the lowest F1-score of 74.8%. These findings further support the superior performance of proposed model compared to other models as shown is Figure 9.
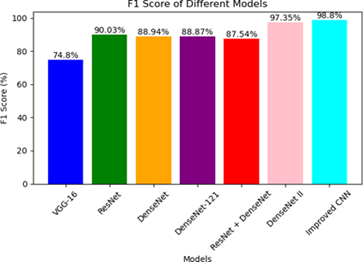
Figure 9: F1 score comparison of few DL models
Conclusion and Future scope
Melanoma has proven to be a more fatal condition than indicated by statistics [1, 22, 15], primarily due to delayed detection and treatment. However, computer-based methods offer a promising solution for the future. While achieving absolute precision in melanoma detection may not be feasible yet, significantly accurate detection provides crucial timely warnings to patients. Our research demonstrates that, particularly for datasets like HAM10000, convolutional neural networks with a customized number of layers outperform other models which use pre-trained models. In future work, we aim to train our model on multiple datasets and train the algorithm to handle a broader range of image inputs. Additionally, our focus will be on enhancing the accuracy and efficiency of our models by incorporating diverse datasets beyond HAM10000, thus increasing their robustness and adaptability.
References
- Cancer. Net Resources
Publisher | Google Scholor - Agarap AF. (2018). Deep learning using rectified linear units (relu). arXiv preprint arXiv:1803.08375.
Publisher | Google Scholor - F. Afza, M. Sharif, M. Mittal, M.A. Khan, D.J. (2022). Hemanth, A hierarchical three-step su- perpixels and deep learning framework for skin lesion classification, Methods 202(2022) 88-102.
Publisher | Google Scholor - R. S, A. S. Bharadwaj, D. S K, M. S. Khadabadi and A. (2022). Jayaprakash, Digital Implementation of the Softmax Activation Function and the Inverse Softmax Func- tion,2022 4th International Conference on Circuits, Control, Communication and Com- puting (I4C), Bangalore, India, 2022:64-67.
Publisher | Google Scholor - D. Bi, D. Zhu, F. Rashid Sheykhahmad, M. Qiao, (2021). Computer-aided skin cancer diagnosis based on a new meta-heuristic algorithm combined with support vector method, Biomed. Signal Process. Control 68 (2021)102631.
Publisher | Google Scholor - Borlea ID, Precup RE, Borlea AB, Iercan D (2021)A unified form of fuzzy C-means and K-means algorithms and its partitional implementation Knowl Based Syst 214:106731
Publisher | Google Scholor - N. Codella, V. Rotemberg, P. Tschandl, M.E. Celebi, S. Dusza. (2018). Halpern, Skin lesion analysis to- ward melanoma detection 2018: A challenge hosted by the international skin imaging collaboration.
Publisher | Google Scholor - Das K, Cockerell CJ, Patil A, Pietkiewicz P, Giulini M, Grabbe S, Goldust M. (2021). Ma- chine Learning and Its Application in Skin Cancer Int J Environ Res Public Health, 18(24):13409.
Publisher | Google Scholor - Girdhar, N., Sinha, A. & Gupta, S. (2022). DenseNet-II: an improved deep convolutional neural network for melanoma cancer detection Soft Computation.
Publisher | Google Scholor - W. Gouda, N.U. Sama, G. Al-Waakid, M. Humayun, N.Z. (2022). Jhanjhi, Detection of skin cancer based on skin lesion images using deep learning, Healthcare, 10(7).
Publisher | Google Scholor - M. Hasan, S.D. Barman, S. Islam, A.W. (2019). Reza, Skin cancer detection using convolutional neural network, in: 5th International Conference on Computing and Artificial Intelli- gence (ICCAI), 254-258.
Publisher | Google Scholor - Ioffe S, Szegedy C. (2015). Batch normalization: Accelerating deep network training by reducing internal covariate shift. In International conference on machine learning, 448-456).
Publisher | Google Scholor - Kukaˇcka J, Golkov V, Cremers D. (2017). Regularization for deep learning: A taxonomy. arXiv preprint arXiv, 1710.10686.
Publisher | Google Scholor - Mehwish Dildar, Shumaila Akram, Muhammad Irfan, Hikmat Ullah Khan, Muhammad Ramzan, et al. (2021). Skin Cancer Detection: A Review Using Deep Learning Techniques” Int J Environ Res Public Health, 18(10):5479.
Publisher | Google Scholor - Miiskin. (2022). Skin tracking and tele dermatology platform, tracking.
Publisher | Google Scholor - R. Mohakud, R. Dash. (2021). Designing a grey wolf optimization based hyper-parameter optimized convolutional neural network classifier for skin cancer detection, J.King Saud Univ. Comput. Inf. Sci.
Publisher | Google Scholor - Mohammad Ali Kadampur, Sulaiman Al Riyaee. (2020).Skin cancer detection: Applying a deep learning based model driven architecture in the cloud for classifying dermal cell images, Informatics in Medicine Unlocked, 18(2020):100282.
Publisher | Google Scholor - Murugan, S. Nair, H. Anu, A. Preethi, Peace Angelin, et al. Diagnosis of skin cancer using machine learning techniques” Microprocess Microsyst, 81(2021):103727
Publisher | Google Scholor - Ontiveros-Robles E, Castillo O, Melin P (2021). Towards asymmetric uncertainty mod- eling in designing General Type-2 Fuzzy classifiers for medical diagnosis Expert Syst Appl 183:115370
Publisher | Google Scholor - C.R. Philipp Tschandl, H. Kittler. (2018). The HAM10000 dataset, a large collection of multi- source dermatoscopic images of common pigmented skin lesions, Sci. Data, 5(2018).
Publisher | Google Scholor - Rezvantalab A., Safigholi H., Karimijeshni S. (2021). Dermatologist Level Dermoscopy Skin Cancer Classification Using Different Deep Learning Convolutional Neural Net- works Algorithms.
Publisher | Google Scholor - S. Saravanan, B. Heshma, A. Ashma Shanofer, R. Vanithamani. (2020). Skin cancer detection using dermoscope images, Mater. 33(2020).
Publisher | Google Scholor - Schoenenberger, L., Schmid, A., Ansah, J. and Schwaninger, M. (2017). The challenge of model complexity: improving the interpretation of large causal models through variety filters. Syst. Dyn. Rev., 33:112-137.
Publisher | Google Scholor - E.M. Senan, M.E. Jadhav. (2021). Analysis of dermoscopy images by using ABCD rule for early detection of skin cancer, Global Trans. Proc., 2(1):1-7.
Publisher | Google Scholor - Shorten, C., Khoshgoftaar, T.M. (2019). A survey on Image Data Augmentation for Deep Learning J Big Data, 6(60).
Publisher | Google Scholor - Srivastava, Nitish & Hinton, Geoffrey & Krizhevsky, Alex & Sutskever, Ilya & Salakhut- dinov, Ruslan. (2014). Dropout: A Simple Way to Prevent Neural Networks from Over- fitting. Journal of Machine Learning Research, 15:1929-1958.
Publisher | Google Scholor - M. To˘ga¸car, Z. C¨omert, B. (2021). Ergen, Intelligent skin cancer detection applying autoencoder, MobileNetV2 and spiking neural networks, Chaos Solitons Fractals 144(2021):110714.
Publisher | Google Scholor - P.P. Tumpa, M.A. Kabir. (2021). An artificial neural network-based detection and classification of melanoma skin cancer using hybrid texture features, Sens. Int. 2(2021):100128.
Publisher | Google Scholor - Yamashita, R., Nishio, M., Do, R.K.G. et al. (2018). Convolutional neural networks: an overview and application in radiology. Insights Imaging, 9:611-629.
Publisher | Google Scholor














